A Tiny OpenGL 2D Batch Renderer

If you rather read code than words, the source is available on GitHub.
This article describes a small batch renderer written in C using modern OpenGL. The goal is to write the minimum amount to code to reduce draw calls. It's not going to be the fastest or the most efficient implementation, but it's probably one of the smallest, for learning purposes.
Below is an example of how the batch renderer can be used to draw a grid of sprites representing aliens:
typedef struct {
// position
float px, py;
// texcoords
float tx, ty, tw, th;
} Alien;
void draw_alien(BatchRenderer *renderer, Texture tex, Alien a) {
r_texture(renderer, tex.id);
float x1 = a.px;
float y1 = a.py;
float x2 = a.px + 48;
float y2 = a.py + 48;
float u1 = a.tx / tex.width;
float v1 = a.ty / tex.height;
float u2 = (a.tx + a.tw) / tex.width;
float v2 = (a.ty + a.th) / tex.height;
r_push_vertex(renderer, x1, y1, u1, v1);
r_push_vertex(renderer, x2, y2, u2, v2);
r_push_vertex(renderer, x1, y2, u1, v2);
r_push_vertex(renderer, x1, y1, u1, v1);
r_push_vertex(renderer, x2, y1, u2, v1);
r_push_vertex(renderer, x2, y2, u2, v2);
}
int main(void) {
// ...
BatchRenderer renderer = create_renderer(6000);
Texture tex_aliens = create_texture("aliens.png");
struct {
float x, y, w, h;
} alien_uvs[] = {
{2, 2, 24, 24}, {58, 2, 24, 24}, {114, 2, 24, 24},
{170, 2, 24, 24}, {2, 30, 24, 24},
};
while (!glfwWindowShouldClose(window)) {
// ...
r_mvp(&renderer, mat_ortho(0, (float)width, (float)height, 0, -1.0f, 1.0f));
float y = 0;
for (int i = 0; i < 15; i++) {
float x = 0;
for (int j = 0; j < 4; j++) {
for (int k = 0; k < 5; k++) {
Alien ch = {
.px = x,
.py = y,
.tx = alien_uvs[k].x,
.ty = alien_uvs[k].y,
.tw = alien_uvs[k].w,
.th = alien_uvs[k].h,
};
draw_alien(&renderer, tex_aliens, ch);
x += 48;
}
}
y += 48;
}
r_flush(&renderer);
// ...
}
}This (incomplete) program produces the image at the top of this article.
How Batch Rendering Works
Without batch rendering, this is how drawing a grid of aliens might look like:
void draw_alien() {
// ...
glBindVertexArray(vao);
glDrawArrays(GL_TRIANGLES, 0, 6); // or glDrawElements()
}
int main() {
while (...) {
for (...) {
draw_alien();
}
}
}Each alien performs a draw call. Six vertices are drawn from the vertex array, which probably describes two triangles that make up a single quad.
A batch renderer avoids making draw calls by setting up a large dynamic vertex buffer object, where vertex data gets written to a buffer every frame and then the buffer gets used in a single draw call. The data itself may contain multiple quads with different vertex positions, texture coordinates, and perhaps tint colour.
A draw call should be performed:
- When the vertex buffer reaches its capacity
- When any uniform values need to change
- When it's the end of the frame
After submitting a draw call, the vertex buffer is "flushed" to set up for the next draw call.
void draw_alien() {
// nothing is actually drawn at this stage.
// data is just being written to a buffer
r_push_vertex(...); // x6
}
int main() {
while (...) {
for (...) {
draw_alien();
}
r_flush(); // this is where glDrawArrays actually gets called
}
}In summary, instead of naively making a draw call for each alien:
draw_alien() writes to a buffer, and then r_flush() performs a single draw
call.
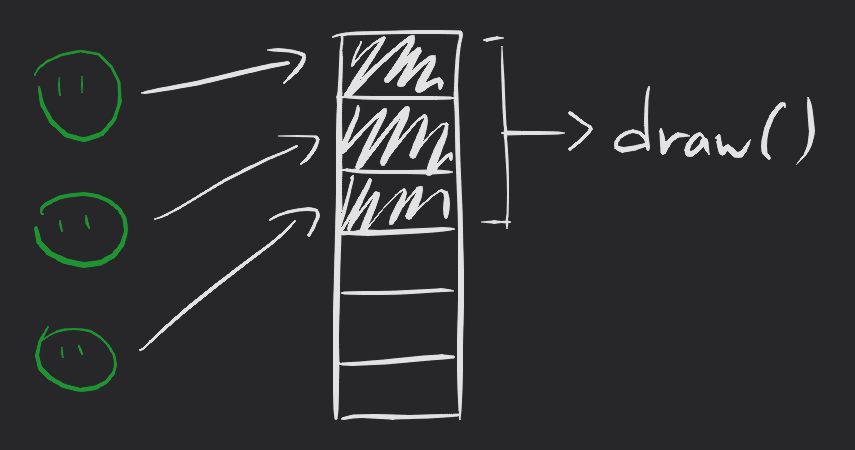
By reducing the number of draw calls, we can increase the performance of our program.
Implementation
The BatchRenderer struct contains a shader program shader, a vertex array
object vao, a vertex buffer object vbo, an array of vertices in CPU memory
vertices, and values that get bound to uniforms texture and mvp.
typedef struct { float cols[4][4]; } Matrix;
typedef struct { float position[2]; float texcoord[2]; } Vertex;
typedef struct {
GLuint shader;
// vertex buffer data
GLuint vao;
GLuint vbo;
int vertex_count;
int vertex_capacity;
Vertex *vertices;
// uniform values
GLuint texture;
Matrix mvp;
} BatchRenderer;The vertices buffer is needed to write vertex data somewhere in CPU memory,
and the vertex buffer object vbo is needed to read vertex data in GPU memory.
To avoid confusion, I'll be referring to the vertex buffer object as the GPU
vertex buffer or VBO, and the array of vertices in CPU memory as the CPU vertex
buffer.
The following function initializes a batch renderer with a given capacity for the CPU vertex buffer:
BatchRenderer create_renderer(int vertex_capacity) {
GLuint vao;
glGenVertexArrays(1, &vao);
glBindVertexArray(vao);
// create the dynamic vertex buffer
GLuint vbo;
glGenBuffers(1, &vbo);
glBindBuffer(GL_ARRAY_BUFFER, vbo);
glBufferData(GL_ARRAY_BUFFER, sizeof(Vertex) * vertex_capacity, NULL,
GL_DYNAMIC_DRAW);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, sizeof(Vertex),
(void *)offsetof(Vertex, position));
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, sizeof(Vertex),
(void *)offsetof(Vertex, texcoord));
const char *vertex =
"#version 330 core\n"
"layout(location=0) in vec2 a_position;\n"
"layout(location=1) in vec2 a_texindex;\n"
"out vec2 v_texindex;\n"
"uniform mat4 u_mvp;\n"
"void main() {\n"
" gl_Position = u_mvp * vec4(a_position, 0.0, 1.0);\n"
" v_texindex = a_texindex;\n"
"}\n";
const char *fragment = "#version 330 core\n"
"in vec2 v_texindex;\n"
"out vec4 f_color;\n"
"uniform sampler2D u_texture;\n"
"void main() {\n"
" f_color = texture(u_texture, v_texindex);\n"
"}\n";
GLuint program = load_shader(vertex, fragment);
return (BatchRenderer){
.shader = program,
.vao = vao,
.vbo = vbo,
.vertex_count = 0,
.vertex_capacity = vertex_capacity,
.vertices = malloc(sizeof(Vertex) * vertex_capacity),
.texture = 0,
.mvp = {0},
};
}The main takeaway is the call to glBufferData(). The usage pattern for the
GPU vertex buffer is GL_DYNAMIC_DRAW instead of something like
GL_STATIC_DRAW. This allows us to change the contents of the GPU vertex
buffer in the future using the glBufferSubData() function. The data parameter
is NULL, which means the VBO data living in VRAM is uninitialized.
I won't go into detail about the load_shader() function since it's nothing
special. The function returns the result of glCreateProgram() after compiling
the given vertex and fragment shaders. The shaders themselves consist of simple
GLSL that would be expected from a basic 2D renderer.
The memory allocated for vertices should be the same size as the VBO, which
is sizeof(Vertex) * vertex_capacity. This array of vertices living in CPU
memory is the buffer that will be written to whenever something needs to be
drawn, but it should not be mutated directly. r_push_vertex() should be used
instead, which does some housekeeping by incrementing vertex_count by one and
it checks when the CPU vertex buffer is at capacity.
void r_push_vertex(BatchRenderer *renderer, float x, float y, float u,
float v) {
if (renderer->vertex_count == renderer->vertex_capacity) {
r_flush(renderer);
}
renderer->vertices[renderer->vertex_count++] = (Vertex){
.position = {x, y},
.texcoord = {u, v},
};
}When the CPU vertex buffer reaches its capacity, then we have no more room to
add another vertex. The solution is to submit a draw call and empty the CPU
vertex buffer with r_flush().
void r_flush(BatchRenderer *renderer) {
if (renderer->vertex_count == 0) {
return;
}
glUseProgram(renderer->shader);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, renderer->texture);
glUniform1i(glGetUniformLocation(renderer->shader, "u_texture"), 0);
glUniformMatrix4fv(glGetUniformLocation(renderer->shader, "u_mvp"), 1,
GL_FALSE, renderer->mvp.cols[0]);
glBindBuffer(GL_ARRAY_BUFFER, renderer->vbo);
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(Vertex) * renderer->vertex_count,
renderer->vertices);
glBindVertexArray(renderer->vao);
glDrawArrays(GL_TRIANGLES, 0, renderer->vertex_count);
renderer->vertex_count = 0;
}This is where glBufferSubData() comes into play. glBufferSubData() is analogous
to memcpy() except it copies from CPU memory into GPU memory instead of
exclusively working in CPU memory. 0 is the offset where data is copied to
(0 being the start of the VBO data). sizeof(Vertex) * renderer->vertex_count is
the number of bytes to copy. renderer->vertices is the data to copy from.
After binding the uniform values, and copying the CPU vertex buffer data to GPU memory,
a draw call is made with glDrawArrays(), and vertex_count is set to 0 to set up
for the next call to r_flush.
Almost done. There's one case that has to be handled: whenever any uniform needs to change, the CPU vertex buffer needs to be flushed before setting the uniform. The following functions are created just for these cases:
void r_texture(BatchRenderer *renderer, GLuint id) {
if (renderer->texture != id) {
r_flush(renderer);
renderer->texture = id;
}
}
void r_mvp(BatchRenderer *renderer, Matrix mat) {
if (memcmp(&renderer->mvp.cols, &mat.cols, sizeof(Matrix)) != 0) {
r_flush(renderer);
renderer->mvp = mat;
}
}That's it! To use the renderer, call create_renderer() during program initialization,
r_push_vertex() when drawing in the main render loop, and r_flush() at the
end of each frame.
The source code for the entire program is available on GitHub.
Improvements
Here is a list of changes that can be made to this renderer to improve its performance and efficiency:
- Store uniform locations to avoid
glGetUniformLocation()inr_flush(). - Create an index buffer to improve efficiency and memory usage when exclusively
drawing quads. Drawing a quad would need four calls to
r_push_vertex()instead of six. - Create multiple buffers and group them based on texture to minimize state changes.